En el primer artículo de esta serie tratamos cómo obtener datos de Twitter desde triggers o disparadores. En este punto deberíamos empezar a pensar qué campos incluimos en nuestro análisis e ir estudiando el formato de los mismos.
Para ello, recomendamos este enlace a la página de desarrollo de la API de Twitter, donde se enumeran todos los campos generados por cada tweet y su formato exacto: https://dev.twitter.com/overview/api/tweets
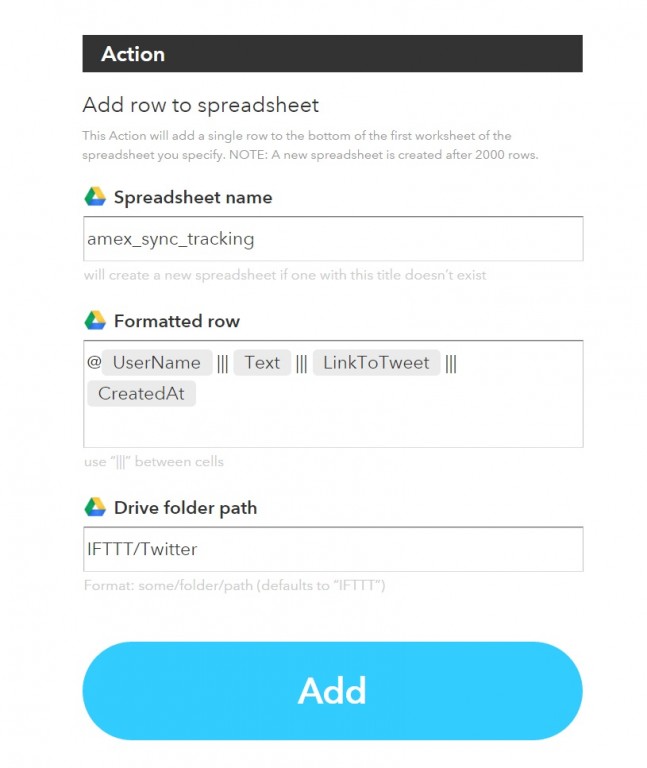
En nuestro caso hemos definido un trigger que nos guarda una fila por cada nuevo tweet con el hashtag #datascience y con un número de retweets mayor a 5.
Los campos que registramos son:
RT | Número de veces que el tweet se ha retweeteado |
Cuenta | Usuario que twittea |
Followers | Número de seguidores del usuario |
URL | URL asociada al tweet |
URL Tweet original | URL original a la que apunta la del tweet |
Text | Texto completo del tweet |
Os dejamos un enlace al documento de hoja de cálculo de Google Apps donde se guardan los datos obtenidos:
![Analítica de hashtags de Twitter con Spreadsheets de Google]()
Enlace al documento de hoja de cálculo, con datos origen y resultados
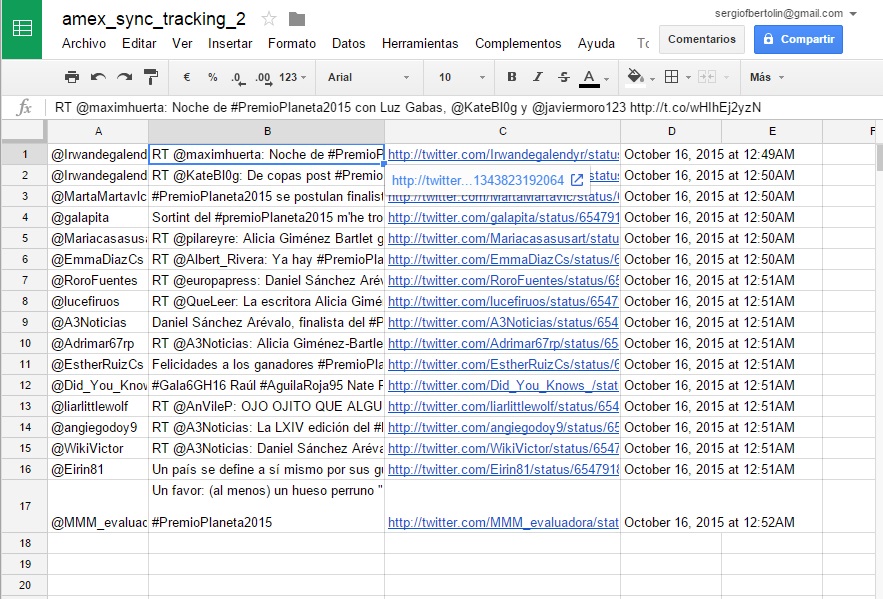
En la pestaña 'DataScience', tenemos los datos almacenados, tal y como se guardan directamente. Es decir, sin aplicar ningún filtrado, limpieza de datos o similar.
En nuestro análisis vamos a buscar los hashtags más exitosos. Para medirlo, usaremos dos criterios diferentes:
- Número de apariciones de hashtag: Consitirá, simplemente, en contar el número de tweets que contienen el hashtag analizado
- RT’s alcanzados por el hashtag: Contaremos la suma total de retweets obtenidos por cada tweet que contenga el hashtag medido
Para hacer esto, lo primero que debemos obtener son los hashtags de cada tweet. Conociendo el formato de los mismos, que comienzan por el carácter “#” y acaban con un espacio, podremos hacerlo directamente en las hojas de cálculo de Google. Lo hemos implementado en la pestaña 'Hashtags' del documento enlazado. Lo primero que encontraremos en la misma, en las columnas A, B, C y D son los primeros 757 registros de tweets de la Pestaña DataScience. A partir de ellos, que ya suponen un número considerable, realizaremos nuestro análisis.
Buscando la posición de inicio de los hashtags
Creamos ahora 9 columnas auxiliares: Hashtag_pos_1, Hashtag_pos_2, … , hasta Hashtag_pos_9. En Hashtag_pos_1 buscamos, empezando por el carácter 1 del campo Text (columna D), la posición de la cadena de caracteres de texto donde hallamos el primer “#”. Dicho de otro modo, donde empieza el primer hashtag. La fórmula de las hojas de cálculo de Google que hace esto es la siguiente, tal y como está en nuestra hoja, en la celda E2:
=find("#";$D2;1)Siendo "#" el carácter buscado, $D2 la referencia a la celda donde tenemos el texto y 1 el carácter donde quiero iniciar la búsqueda.
Para hallar el segundo hashtag deberemos buscar de forma análoga el mismo carácter, pero ahora empezando en la posición donde se hallaba el anterior +1, para no volver a obtener el mismo resultado. Ponemos la fórmula usada en la celda F2 como ejemplo:
=find("#";$D2;E2+1)Como vemos el carácter buscado es el mismo, buscamos en el mismo texto $D2 haciendo la misma referencia y lo que cambia es el tercer parámetro, que utiliza la posición obtenida para el carácter “#” del primer hashtag y le suma uno para obtener el siguiente.
Así, encadenamos la búsqueda de estos resultados hasta el número máximo de hashtags que creamos que vamos a obtener. En nuestro caso lo hemos hecho para obtener un máximo de 9, y vemos que el máximo encontrado ha sido de 8.
¿Cómo sé que el máximo obtenido ha sido 8? Porque la última columna, la de Hashtag_pos_9 no obtiene ningún resultado válido, son todo #VALUE!
El siguiente paso será extraer los hashtags.
Extrayendo los hashtags
Haré uso ahora de las posiciones de inicio de cada hashtag. Deberé extraer texto de mi tweet empezando por la posición encontrada hasta que encuentre un espacio. Usaremos la fórmula de la celda N2
=iferror(mid($D2;E2;find(" ";$D2;E2+1)-E2);" ")Analizar toda la fórmula de golpe puede ser un poco complejo… La función “iferror”, la última en aplicarse, nos cambia los resultados de error por un espacio en blanco en lugar de mensaje de error. Esto es muy conveniente para luego poder aplicar otras fórmulas a los textos de hashtags extraídos. Lo hacemos mediante el siguiente comando:
=iferror(HASHTAG_EXTRAIDO;" ")
Pasamos ahora a analizar el bloque correspondiente al HASHTAG_EXTRAIDO, devuelto por la siguiente fórmula:
HASHTAG_EXTRAIDO = mid($D2;E2;find(" ";$D2;E2+1)-E2)En esta fórmula $D2 indica el texto de donde extraer caracteres, E2 indica el carácter inicial a extraer, que es el primer carácter “#” encontrado y el tercer parámetro es el número de caracteres a extraer, que calculamos restando la posición del espacio y la de inicio del hashtag:
find(" ";$D2;E2+1)-E2Obtenemos la posición del primer espacio después del hashtag con la fórmula find(" ";$D2;E2+1), y E2 es directamente la posición de inicio del hashtag, calculada anteriormente.
Aplicando esta operación en las sucesivas columnas obtenemos todos los hashtags de los textos.
Ahora pasaremos a aplicar la operación más compleja del ejemplo, que es extraer todos los resultados únicos de etiquetas.
Extrayendo resultados únicos
Extraer resultados únicos de una sola columna en hojas de cálculo de Google es rápido y fácil con la función unique. Aquí nuestro problema radica en que tengo los datos en 8 columnas distintas. La función citada, si selecciono más de una columna, compara los valores por filas completas, no los de cada celda en particular. La solución más rápida sería copiar los valores de las 8 columnas a una sola. Mi objetivo, no obstante, es usar una fórmula que me permita un cálculo automatizado sin tener que andar copiando y pegando columnas manualmente.
Realizamos este proceso con la fórmula de la celda W2, en una fórmula con diversas operaciones anidadas:
=unique(transpose(split(ArrayFormula(concatenate(N2:U757&" "));" ")))
Paso a paso, estamos haciendo lo siguiente:
Ponemos todas las etiquetas obtenidas en una única secuencia de caracteres, donde cada etiqueta estará separada de la anterior por un espacio en blanco.
SECUENCIA_UNICA = ArrayFormula(concatenate(N2:U757&" "))
Separamos ahora los elementos de la secuencia de caracteres obtenidos en diversas columnas. Cada vez que encuentra un espacio crea una nueva columna. Esto me generará una lista con todas las etiquetas en una sola fila.
=split(SECUENCIA_UNICA;" ")
Nos queda, por tanto, pasar nuestro resultado de una sola fila a una sola columna, cosa que realizamos con la función transpose.
=transpose(split(SECUENCIA_UNICA;" "))
Y para finalizar, lo que estábamos buscando desde el principio, la lista de valores no repetidos de hashtags, extraída con la fórmula unique que ahora sí funciona bien porque nuestros datos ya están en una sola columna.
=unique(transpose(split(SECUENCIA_UNICA;" ")))
Finalmente, con nuestra lista de valores únicos podemos realizar los dos tipos de cálculos que teníamos previstos.
Obteniendo el número de apariciones de un hashtag
Ahora, como se muestra en la columna X, la etiquetada como repeticiones y la inestimable ayuda de la fórmula “countif”, aplicada sobre la lista completa de hashtags, obtenemos el número de repeticiones para cada entrada. Aplicamos esta fórmula:
=countif(N$2:U$757;W2)
N$2:U$757 corresponde a la lista completa de todos los hashtags y W2 a la entrada particular que estamos buscando y contando. Es importante poner los caracteres de dólar ($) para que en las sucesivas filas la fórmula cuente siempre buscando dentro de la misma lista de elementos.
Una vez obtenida la lista completa de hashtags queremos ordenarlos por número de apariciones, de mayor a menor y que este cálculo quede automatizado también. Nos encargamos de ellos con la fórmula “sort”, seleccionando la lista de valores únicos con su correspondiente número de repeticiones (W2:X69) como primer parámetro. Ponemos un 2 como segundo parámetro, haciendo que ordene la lista por número de repeticiones y FALSE como tercer parámetro, para ordenar de mayor a menor:
=sort(W2:X69;2;FALSE)
Así, en esta aplicación concreta nuestros resultados más repetidos son, en ese orden:
- DataScience
- datascience
- BigData
- bigData
- abdsc
- Analytics
- MachineLearning
- machinelearning
- datascience?
- DeepLearning
La función que cuenta los resultados no distingue entre mayúsculas y minúsculas, por eso DataScience y datascience salen con el mismo número de repeticiones.
Este resultado, no obstante, sólo valora las veces que es etiquetada una temática en los tweets de #DataScience, pero no valora la repercusión final o la llegada al público.
Valorando el alcance de los tweets por hashtag utilizado
Para medir la repercusión de cada etiqueta usaremos el criterio de número total de retweets obtenidos por cada uno de ellos.
Creamos primero unas columnas auxiliares para cada hashtag a analizar, donde aparecerá un 1 si el texto del tweet lo contiene y un 0 si no. Analizamos los 5 resultados con más apariciones según la ordenación del apartado anterior. Una vez obtenido este resultado binario lo multiplicaremos por el número de retweets y obtendremos el alcance global de cada etiqueta.
Empezamos entones. Para ver si la etiqueta analizada aparece en cada tweet concreto usamos ahora la función “find” que SÍ distingue entre mayúsculas y minúsculas y podremos ver si realmente un grupo tiene mayor repercusión según si se escriben algunos caracteres con mayúsculas o no:
=FIND($Z$3;$D2)
La función en las líneas superiores busca el texto “#DataScience” y si lo encuentra devuelve un número entero indicando el carácter donde comienza. Si no lo encuentra devuelve un error. Así, para obtener el resultado binario explicado anteriormente usamos la siguiente función:
=IF(IFERROR(FIND($Z$3;$D2);0)>0;1;0)
Con la función “iferror”, transformamos los errores en el valor 0 y los números enteros quedan igual. Posteriormente, con la función “if”, cambiamos los enteros que nos indican la existencia de la etiqueta en un 1 y dejamos el resto de valores en 0.
Para concluir, sólo nos queda multiplicar el número de RT de cada tweet por el 1 o el 0 que nos indica si la etiqueta en concreto está o no. Como ejemplo, la función usada para calcular los retweets logrados con el hashtag DataScience.
=SUMPRODUCT($A$2:$A$757;AC2:AC757)
Donde el parámetro $A$2:$A$757 se refiere a la columna con los RT’s de cada entrada y el segundo parámetro, AC2:AC757 al indicador de si la etiqueta está o no.
Podemos ver ahora que, según el criterio elegido, la influencia de las etiquetas es bastante más dispar que la obtenida anteriormente.
Etiqueta | Número de apariciones | Número de RT’s |
#DataScience | 677 | 20485 |
#datascience | 34 | 707 |
#BigData | 478 | 14735 |
#bigdata | 14 | 162 |
#abdsc | 226 | 7596 |
Vemos así como #abdsc obtiene proporcionalmente pocos retweets en comparación con los que obtienen #BigData y #DataScience.
Por otro lado, los resultados de #bigdata y #datascience, obviando las mayúsculas en lugar que les corresponde, son extremadamente inferiores a los que sí escriben las iniciales con mayúsculas.
Los criterios y condiciones a aplicar son mejorables, especialmente las agrupaciones de diversos hashtags similares dentro del mismo grupo, pero este artículo se enfoca a la utilización de Zapier y de las hojas de cálculo de Google Apps para obtener resultados trascendentes. Así, según nuestro análisis, la etiqueta BigData es, con diferencia, la que más retweets consigue. Faltaría, por ejemplo, obtener el ratio de retweets conseguidos por apariciones de etiqueta, que nos daría una idea de la efectividad real de cada una de ellas. Pero eso ya lo dejamos en vuestra mano.











 para los que buscan tendencias locales o globales. No sólo eso, sino que podemos encontrar rápidamente los personajes o ideas más influyentes en dicha red analizando los datos que nos proporciona la API de Twitter.
para los que buscan tendencias locales o globales. No sólo eso, sino que podemos encontrar rápidamente los personajes o ideas más influyentes en dicha red analizando los datos que nos proporciona la API de Twitter.



















 Dentro de las actividades de análisis de datos, está el análisis exploratorio de los datos fuente. Datos fuente que se utilizarán en diferentes tipos de procesos: integración de datos, reporting, modelos predictivos, etc..
Dentro de las actividades de análisis de datos, está el análisis exploratorio de los datos fuente. Datos fuente que se utilizarán en diferentes tipos de procesos: integración de datos, reporting, modelos predictivos, etc..
 En clustering se deja que los datos se agrupen de acuerdo a su similitud. Estos modelos son agrupaciones de segmentos -clusters- que contienen casos, tales como clientes, pacientes, autos, etc.
En clustering se deja que los datos se agrupen de acuerdo a su similitud. Estos modelos son agrupaciones de segmentos -clusters- que contienen casos, tales como clientes, pacientes, autos, etc.
 Los outliers, (o "valores extremos"), son un tema siempre presente cuando se analizan datos, sin importar el origen de los mismos.
Los outliers, (o "valores extremos"), son un tema siempre presente cuando se analizan datos, sin importar el origen de los mismos. El siguiente análisis está realizado con el lenguaje R y la libreria Google Vis para la visualización de gráficos. Es tan importante medir la esperanza de vida así como también la calidad de la misma. Se analizarán datos de eurostat basados en las variables Healthy life years y Life expectancy..
El siguiente análisis está realizado con el lenguaje R y la libreria Google Vis para la visualización de gráficos. Es tan importante medir la esperanza de vida así como también la calidad de la misma. Se analizarán datos de eurostat basados en las variables Healthy life years y Life expectancy.. La semana pasada asistí a un encuentro de RugBcn, el Grupo de Usuarios de R de Barcelona, que tenía por objetivo mostrar cómo crear informes automáticos directamente desde R gracias a las librerías rmarkdown y knitr. El título del evento era 'Automatic Reporting with rmarkdown'..
La semana pasada asistí a un encuentro de RugBcn, el Grupo de Usuarios de R de Barcelona, que tenía por objetivo mostrar cómo crear informes automáticos directamente desde R gracias a las librerías rmarkdown y knitr. El título del evento era 'Automatic Reporting with rmarkdown'..













